Googleの人工知能DeepDreamは、LSDで幻覚を見てるような画像、常軌を逸した画像、の作成機というわけではなく、実は技術的に大きな進化だ。人工知能が「特徴を自ら認識」するというところがすごいところ。我々人間が脳で行っている認識するという神経細胞メカニズムを、これだけ機械が模倣できたことは今までにないと思う。人工知能が自分が知ってるものをベースにして、提示された画像はこんな風に見えるな、という感じで、融合した結果画像を生成していくわけだ。
しかもgithubでソースが公開されているので、環境構築ができれば誰でも使うことができる。さっそく画像をDeepDreamに見せてみたら、
国宝松本城は、周りになんか車のような物体が出てきて、天守もキリスト教伝来みたいな状態に。


去年イタリアに行ったときに撮ったフィレンツェの美術館の写真は、ことごとくワンちゃんの顔に。


安藤広重の東海道五十三次・日本橋は、人通り増えた感が。


いくつかDeepDreamしてみたのを動画にまとめるとこういう感じ。悪夢。
DeepDreamを動かしてみる
DeepDreamを含めて、Deep Learningでは大量の計算コストが発生するので、CPUではなくGPUで計算させるのが一般的だ。さらにそのGPUも、NvidiaがCUDAというハイパフォーマンス環境を提供しているので、Nvidia製の必要がある。また、Deep Learningの画像処理といえばCaffeというフレームワークがスタンダードになっている。
条件が色々あってハードウェアから揃えるのは面倒、そういう時に頼りになるのがAWS。AWSのAMIで提供されている環境があるのでそれを使えばすぐにDeep Learningを始められる。
参考URL:CUDA 6.5 on AWS GPU Instance Running Ubuntu 14.04とRunning Caffe on AWS GPU Instance via Docker。(単純に実行してみたいというだけならWeb interface for Google Deep Dreamもある。)
AWSインスタンス作成
ずっと使い続けるものでなければ、コストが安いスポットインスタンスで十分だろう。スポットインスタンスとは、AWSサーバリソースを入札形式で購入できるのでオンデマンドに比べて安く使える仕組み。ただし、需給バランスが変わって入札価格より流通価格が上回ったらすぐにターミネートされる。
インフラは再利用性も考えてPackerでスクリプトから作りたいところだけど、Packerスクリプトでspot_priceを設定するとエラーが出て進まなかったのでここではAWSマネジメントコンソールから作成する。
必要なスペックは、
・ami-2cbf3e44 for US-East または ami-c38babf3 for US-West
・Ubuntu Server 14.04 LTS (HVM) – CUDA 6.5
・インスタンスタイプはGPUを使うので、g2.2xlarge
・ストレージは20GB
この情報をもとに構築していく。
AMIが提供されているのが米国東部か米国西部なので、AWSマネジメントコンソールで米国東部(バージニア北部)にリージョン設定。EC2で「スポットインスタンスのリクエスト」をクリック。AMI選択で「ami-2cbf3e44」を検索すると、イメージがあるのでそれを選択。

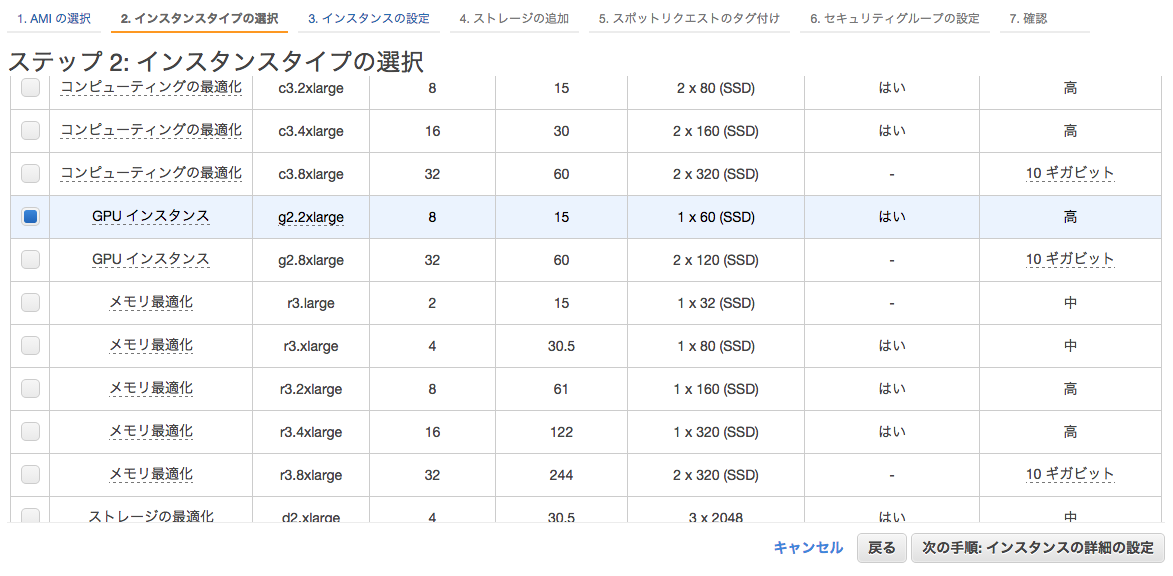
インスタンスタイプは「g2.2xlarge」を選択。g2.2xlargeは1,536CUDAコアを搭載してるらしい。
スポットインスタンスの入札価格を設定する。今回は「$0.08/h」にしてみた。

ストレージ構成は、/dev/sda1に8G以上、/dev/sdbに20G。ライブラリの展開等で必要なので、/dev/sda1は20Gくらい多めにとっておいた方がいい。

しばらく待つと落札されて、通常通りインスタンスが使えるようになるので、pemキーを使ってSSHログインする。
CUDAが正しくインストールされているかの検証
$ cd /usr/local/cuda/samples/1_Utilities/deviceQuery $ make $ ./deviceQuery
を実行して、
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 6.5, CUDA Runtime Version = 6.5, NumDevs = 1, Device0 = GRID K520 Result = PASS
と表示されればOK。
dockerインストール
CaffeがGPUで動くようにdockerを設定しておく。
$ sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys 36A1D7869245C8950F966E92D8576A8BA88D21E9 $ sudo sh -c "echo deb https://get.docker.com/ubuntu docker main > /etc/apt/sources.list.d/docker.list" $ sudo apt-get update $ sudo apt-get install lxc-docker
$ DOCKER_NVIDIA_DEVICES="--device /dev/nvidia0:/dev/nvidia0 --device /dev/nvidiactl:/dev/nvidiactl --device /dev/nvidia-uvm:/dev/nvidia-uvm" $ sudo docker run -v /tmp:/opt/caffe/misc -ti $DOCKER_NVIDIA_DEVICES tleyden5iwx/caffe-gpu-master /bin/bash
わずか20分くらいでDeep Learningに使えるマシンが完成。すごい時代だ。docker runした後は、Caffeがインストールされたコンテナ環境での作業になるので、/tmpをファイル転送のためにマウントしてある。
DeepDream実行
DeepDreamを実行するために必要なものは、スクリプトとターゲット画像の2つだけ。Googleが公開しているスクリプトはipython notebook形式で、解説なども含まれているためpythonスクリプトだけにしたものを使う。GPUで処理するためにcaffe.set_mode_gpu()を追加してある。
このスクリプトとtarget.jpgを/tmpにSFTPすれば、/opt/caffe/miscで使うことが出来るようになる。Googleのドキュメントに従ってモデルをダウンロード。
$ cd /opt/caffe/models/bvlc_googlenet $ wget http://dl.caffe.berkeleyvision.org/bvlc_googlenet.caffemodel
DeepDreamを実行する。
$ cd /opt/caffe/misc $ python deepdream.py
GPUなので次々と処理が進んでいき、frames/にブッとんだ画像が格納される。

